Real-Time Voice Assistant Prototype
A self-initiated R&D project exploring voice-controlled workflows using OpenAI’s Whisper and Chat APIs. The goal was to create an intuitive, fast-response voice interface that could parse natural speech and respond in real-time, designed before these tools were widely productized.
About The Project
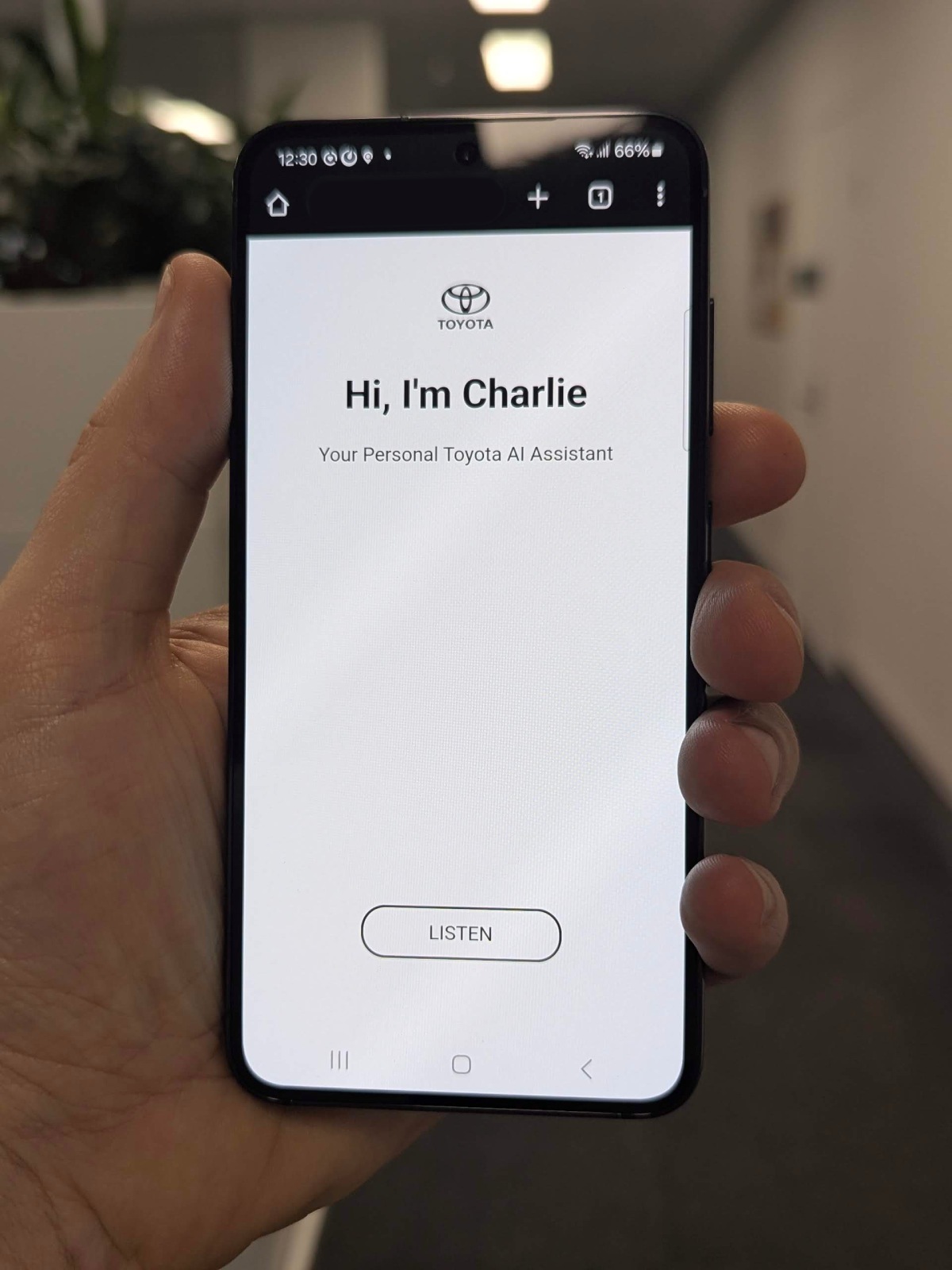
This prototype was an early exploration into building a lightweight voice assistant capable of driving real-time UI changes through natural conversation. Designed for a mobile vehicle configurator, the assistant allowed users to speak freely without rigid command structures and see their intent translated into in-app actions, such as selecting a vehicle grade or changing the paint colour. It was designed to feel more like a quick, casual chat than a traditional voice UI.
At its core, the system used OpenAI’s Whisper model for speech-to-text transcription. The transcript was then fed into the OpenAI Chat API, along with a carefully structured system prompt that provided instructions, guardrails, and embedded business logic. The assistant’s responses weren’t just conversational, they included embedded UI triggers formatted in a custom syntax that could be parsed and executed by the host application.
A major part of the assistant’s design was the use of prompt-based programming rather than model fine-tuning. I provided the API with a layered instruction set that defined personality (“Charlie”), interaction style (e.g. speaking aloud within 15 seconds), formatting constraints, and a full catalog of product-specific actions, options, and exclusions. Each response was expected to balance natural tone with structured action syntax, effectively turning freeform user speech into safe, deterministic UI events.
The result was a flexible and responsive assistant that could react to voice input in under two seconds, guide users through a multi-step journey, and maintain a personable tone throughout. It handled dynamic conditions like checking the current scene before triggering navigation, and redirected off-topic queries back toward product features. The architecture prioritized debuggability, adaptability, and speed offering a practical model for low-latency voice control in real-world interactive applications.
Key Features
Natural Language Control
Users could speak flexibly, no rigid syntax required and the assistant interpreted contextual intent effectively.
Fast Response Loop
Voice-to-action pipeline typically completed in 1–2 seconds, including transcription, response generation, and feedback.
Rule-Based Prompt Design
Used example-driven system prompts and clear formatting to avoid hallucinations and ensure reliable behavior.
Text-to-Speech Feedback
Integrated ElevenLabs voice synthesis for natural-sounding confirmation and assistant personality.
Process & Technical Insights
Process & Technical Insights
Rather than training a custom model, I relied on structured prompt engineering to control scope, inject memory, and guide the assistant’s tone and format. This made iteration much faster and more transparent, especially while debugging behaviors and edge cases.
Latency was minimized by keeping Whisper transcription local and optimizing the Chat API calls with compact context. Most of the complexity was in designing prompts that were both flexible and safe able to respond intelligently without going off-script.
Got questions?
Feel free to reach out